Sombriks Has A Plan
Don't do DTO's if you can
When I have to use entities, I often model them in a way they go well with any serialization strategy. That way I keep things DRY.
In other projects that I just inherited, however, this is not the case and is common place to find an entire Data Transfer Object layer dangling out in the source code.
That strategy have its motivations and consequences, and like everything else in the systems architecture, it's a matter of good practices, someone opinion and compromise.
DT-what?
The Data Transfer Object (or DTO) is a design pattern that aims to better control how data will be presented.
If you use raw queries, data mappers or Entities to interface with database then there is a change that you used DTO's before.
Key benefits, when applied properly, are:
- Data schema from database decoupled from application data
- Data transformation when needed
A sample entity and it's DTO companion would look like this:
@Entity
public class Employee {
@Id
private Long id;
private String firstName;
private String lastName;
@ManyToMany
private Set<Department>departments;
// other attributes and getters/setters
}public class EmployeeDTO {
private Long id;
private String fullName;
// a few other attributes and getters/setters
}We can perform small modifications on the output of a query during entity -> DTO transformation.
Pitfalls
On the other hand it is exactly as it sounds, data duplication, at least at a certain degree.
There are several opinionated ways to implement this design pattern and people tend to be passionate about them.
There are also several bad takes on how to apply code DTO's consequences.
Transformation layer
Assuming you have an Entity Layer (due to the use of JPA or something), you'll need to transform from your entity to the desired DTO.
The common mistake here is the violation of 'layers of intimacy' design pattern:
// this is bad
EmployeeDTO dto = Employee.toDTO(ent);
Employee entity = EmployeeDTO.toEntity(dto);The static helper functions here create coupling between the entity layer and the transfer layer. Entities are supposed to only worry about the database and operations involving it. DTO's need to know about the entity.
Libraries like MapStruct or Spring Converters help to mitigate this intimacy issue but on the other hand introduce a third party dependency for a problem completely solvable with good practices.
Things also get a little better when your conversions are one-way conversions: Entities can pass through your requests and the DTO's play they roles only when you need to produce responses.
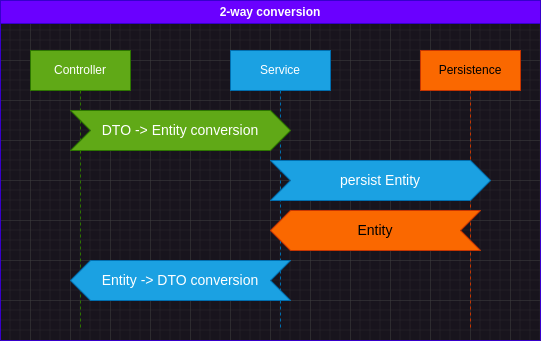
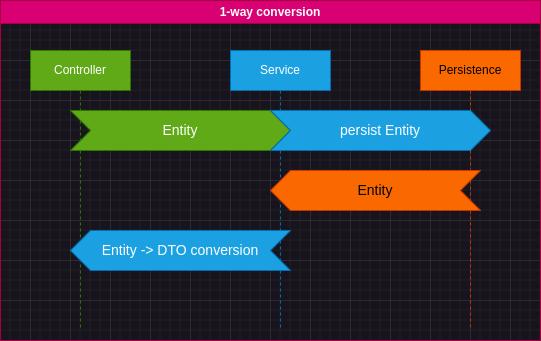
Go with 1-way when possible, it's better
Extension methods
Another approach adopted in projects using languages that supports it is to hand the conversion to extension methods.
@Entity
open class Employee(
@Id
var id: Long? = null,
var firstName: String? = null,
var lastName: String? = null,
@ManyToMany
var departments: Set<Department> = HashSet()
)data class EmployeeDTO(
val id: Long?,
val fullName: String?
)Then your conversion helper could be something like this:
fun Employee.toDTO() = EmployeeDTO(
this.id,
this.firstName + " " + this.lastName
)And this is good now:
val dto = entity.toDTO();Extension methods introduces similar issues to regular conversion helpers but are more idiomatic and easy to the eye... which is important. Also they tend to make easy to decide where to put them inside your project.
Still, DTO's and companion conversion boilerplate become your responsibility to maintain and evolve once adopted.
Another View for the problem
Instead of focusing on create new shapes for the same data, one could use metadata to point out which details should be exposed when passing data ahead.
This is where EntityView enters.
It is data transformation like DTO's but thinner, as you can see in the Blaze homepage exmple:
// define a view
@EntityView(Cat.class)
public interface CatNameView {
@IdMapping
public Long getId();
@Mapping("name")
public String getCatName();
}
// make persistence layer aware of it
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class);
CriteriaBuilder<CatNameView> catNameBuilder = evm.applySetting(EntityViewSetting.create(CatNameView.class), cb);
List<CatNameView> catNameViews = catNameBuilder.getResultList();There is a huge resemblance with one-way DTO mapping. If someone asks me i would say that Entity View design pattern is some sort of evolution of one-way DTO.
Jackson JsonView
Another sample implementation of that approach is Jackson's JsonView.
It's not tightly coupled with any entity frameworks but follows the metadata philosophy:
// create the metadata
public class EmployeeView {
public static class Visible {
}
}
// annotate your entity
@Entity
public class Employee {
@Id
@JsonView(EmployeeView.Visible.class)
private Long id;
private String firstName;
private String lastName;
@ManyToMany
private Set<Department>departments;
@JsonView(EmployeeView.Visible.class)
public String getFullName(){
return firstName+" "+lastName;
}
// other attributes and getters/setters
}
// use proper serialization
ObjectMapper mapper = new ObjectMapper();
mapper.disable(MapperFeature.DEFAULT_VIEW_INCLUSION);
String result = mapper
.writerWithView(EmployeeView.Visible.class)
.writeValueAsString(entity);One disadvantage is we get less flexibility (example, we had to create a
getFullName method and annotate it with @JsonView) when compared with DTO's
but metadata keeps simple to track.
Records as a form of DTO
Modern java projects can use Java Records on JPA constructor expressions to achieve similar results with much less noise:
@Entity
public class Employee {
@Id
private Long id;
private String firstName;
private String lastName;
@ManyToMany
private Set<Department>departments;
// other attributes and getters/setters
}public record EmployeeRecord(
Long id,
String fullName){}Then you query your database entity but returns a record:
TypedQuery<EmployeeRecord> q = em.createQuery("""
select new my.example.EmployeeRecord(
e.id, concat(e.firstName, ' ', e.lastName)
) from Employee e
""");
List<EmployeeRecord> results = q.getResultList();Using records for the DTO job is fine, records make great DTO's.
They also are more closer to metadata style because it's compact definition.
The big drawback is the dependency on JPA constructor expressions, they aren't statically typed.
No model at all
Finally, if you have a dynamic language, you can keep no model at all.
Keep validations, but return data the way it need to be.
Som node query builder frameworks like Knex can solve it for you:
const employees = await knex("employee")
return employees
.map(({id, firstName, lastName}) =>
({id, fullName: firstName+' '+lastName}))Conclusion
This article is just a long rant about pass data through several application layers.
Things sometimes need to be transformed into something else due to various reasons, either business, technical limitations or just because.
It is important to know the consequences of any approach.